Recently I've been asked how to use Active Directory as the Key Distribution Center (KDC) for NFS, especially when used with NetApp filers and Linux 2.6 clients.
At the theoretical level, I've always know this was possible. I've used Solaris 10 NFSv[234] clients with filers configured to use Active Directory. I've used
CITI's early access
NFSv3 w/
Kerberos V5 authentication stuff for Linux 2.4 with filers using Active Directory. And of course, back in my Sun days, I led the team that proved NFS clients and servers could authenticate via Active Directory, work which to this day is the
best documented example of how to do so.
But now that Linux 2.6 with NFSv4 and NFS/Kerberos V5 authentication is getting more real, does this still work, and if so, with all 3 NFS versions? It is a reasonable question, since Linux 2.6 continues to change.
I'm happy to report that with Windows 2000 (
and 2003!) as the KDC, Fedora Core 3 (Linux
2.6.11-1.27_FC3) as the NFS client, and Data ONTAP 7.0.0.1 as the NFSv4 server, the answer is yes, at least as measured by this trivial sanity checking script:
#!/bin/sh
# NFS/Kerberos sanity.sh for Linux 2.6
if [ $# -lt 3 ]
then
echo Usage: $0 server_name server_export mount_point
echo example:
echo " " $0 mre1.sim /vol/vol0/home /mnt
exit 1
fi
size=1m
file=$size.$$.`uname -n`
echo file = $file
serv=$1
fs=$2
mnt=$3
cd /
sudo umount -f $mnt
for proto in tcp udp ;
do
case $proto in
udp )
moreopts=",rsize=4096,wsize=4096"
;;
* )
moreopts=""
;;
esac
for vers in 2 3 4 ;
do
if [ $proto = udp ] && [ $vers = 4 ]
then
echo NFSv4 is not supported over udp
else
for sec in sys krb5 krb5i ; # krb5p ;
do
echo ----------------------------------------
case $vers in
4 )
opts="-t nfs4 -o proto=$proto,sec=${sec}$moreopts"
;;
* )
opts="-o vers=$vers,proto=$proto,sec=${sec}$moreopts"
;;
esac
if sudo mount $opts $serv:$fs $mnt ;
then
cd $mnt
mount | grep -w $mnt
rm -f $file
if time dd if=/dev/zero of=$file bs=1024 count=1024 ;
then
echo $opts PASS
rm -f $file
else
echo $opts FAIL
exit 1
fi
else
echo sudo mount $opts failed. FAIL
exit 1
fi
cd /
sudo umount -f $mnt
done
fi
done
done
But before one runs this script, some configuration on the KDC, the Linux client, and the ONTAP filer are necessary.
Let's look at the KDC.
I am assuming that an Active Directory realm has been created. My example uses ADNFSV4.LAB.NETAPP.COM as the Kerberos realm.
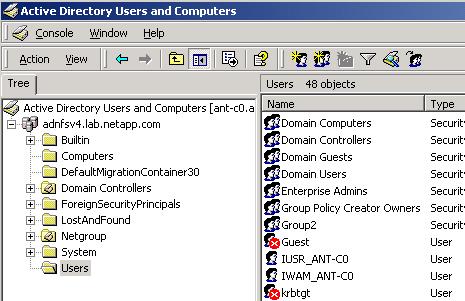
The first thing we need to create are users. Let's walk through an example for creating a user named jsmith. First thing we do is highlight the Users folder in Active Directory:
Highlight Users Folder
Windows Server 2000 Screenshot
Having done that, right click in the folder to pop up the action menu for the folder:
Pop Up Action Menu for Users
Windows Server 2000 Screenshot
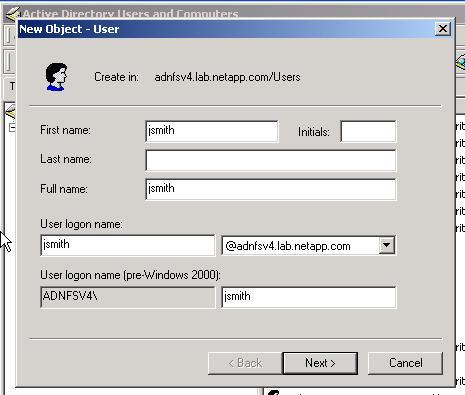
Pick the New --> User option. Now we fill in the information. I find that the First name, Full name, and User login name have to agree with each other, but you may have a different experience:
Fill in Information for New User
Windows Server 2000 Screenshot
Now click next to get to the password setting window:
Password for New User
Windows Server 2000 Screenshot
Finally, we get to the confirmation window. Click finish to complete adding the user:
Confirmation Window for New User
Windows Server 2000 Screenshot
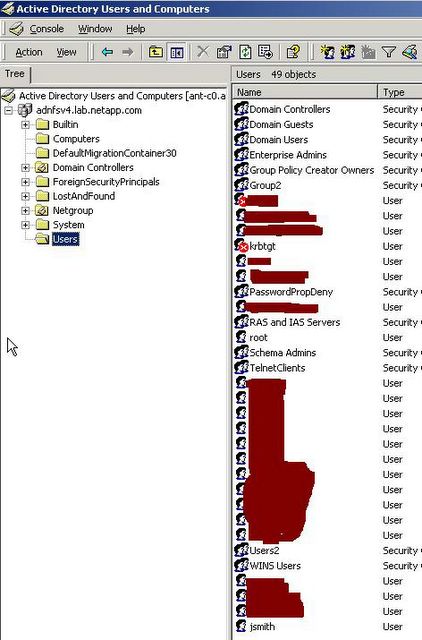
Now we see that the user, jsmith, is in the Users folder of the Active Directory realm:
Active Directory listing for ADNFSV4.LAB.NETAPP.COM realm
Windows Server 2000 Screenshot
Now we need to create a "machine" credential for the Linux NFS client. Currently, Linux 2.6 requires a credential of form:
nfs/hostname@REALM-NAME
Our host name will be scully.lab.netapp.com. The realm name is ADNFSV4.LAB.NETAPP.COM.
We start by creating yet another
User principal.
You must create this principal as type
User. Do
NOT create the principal as type
Computer. There is some dispute about this.
Mario Wurzl says that he has no problem creating machine credential principals as type
Computer. However, Microsoft's
Kerberos Interoperability document says otherwise:
Use the Active Directory Management tool to create a new user account for the UNIX host:
- Select the Users folder, right-click and select New, then choose user.
- Type the name of the UNIX host.
The above passage is taken from a series steps for creating a principal of form host/
hostname@
REALM. We are ultimately going to create a principal of form nfs/
hostname@
REALM, so I contend the above excerpt from Microsoft applies. It may be the case that principals of type Computer work fine for machine credentials. I have never tried that, and absent a compelling reason, won't try it.
As we will see, this principal can be any name, but let's use a convention:
servicenameNot-fully-qualified-hostname
E.g. concatenate the service name "nfs" with the capitalized base hostname "Scully". So, our new principal will be:
nfsScully
You might be asking: "Whoa, where did this weird convention come from? Why not just call the principal ``scully''"? The issue is that you may find you need multiple machined credentials for various services. You might need host/
hostname@
REALM, nfs/
hostname@
REALM and root/
hostname@
REALM. You can't call the user principal for all three of these
hostname. Credit goes to my old
Kerberos project team at Sunfor coming up with this convention.
OK. Repeat the steps used to create principal jsmith in the
Users folder for principal nfsScully.
The next step requires opening a Command Prompt window on the Windows 2000 server, and mapping nfsScully to its real machine principal,
nfs/scully.lab.netapp.com@ADNFSV4.LAB.NETAPP.COM
The command to do is ktpass, and it is invoked as:
ktpass -princ nfs/scully.lab.netapp.com@ADNFSV4.LAB.NETAPP.COM -mapuser nfsScully -pass XXXXXXXX -out UNIXscully.keytab
I have deliberately italicized the XXXXXXXX in the above to indicate that a real password needs to be provided (This password
does not have to be the same as that used when user principal nfsScully was created in the Active Directory GUI. In fact, I've never used the same password for the GUI and the ktpass command.
I cannot claim if this will work if the passwords are the same). You should generate password XXXXXXXX randomly, lest an attacker tries to impersonate Linux client scully. And you should be doing all this on a secure connection to the Windows 2000 server, lest an attacker packet sniff your session and grab the password. Here is a screen shot of the above example:
ktpass example
Windows Server 2000 Screenshot
You would then securely copy UNIXscully.keytab to
scully.lab.netapp.com:/etc/krb5.keytab
using a tool like scp (SSH for file copy). Note that it is possible on the Linux client to kinit to nfsScully via password XXXXXXXX. I think this is unfortunate. Machined credential passwords should use randomly generated keys that even you the system administrator don't know the password for. Randomly generate XXXXXXXX blind if possible, such via a .bat script under the Windows 2000 command shell.
Now it is time to focus attention on the Linux client.
Log onto the Linux client, and create an /etc/krb5.conf file. Here is an example:
[libdefaults]
default_realm = ADNFSV4.LAB.NETAPP.COM
default_tkt_enctypes = des-cbc-md5 ; or des-cbc-crc
default_tgs_enctypes = des-cbc-md5 ; or des-cbc-crc
[realms]
ADNFSV4.LAB.NETAPP.COM = {
kdc=ant-c0.lab.netapp.com:88
default_domain=lab.netapp.com
}
[domain_realm]
.netapp.com = ADNFSV4.LAB.NETAPP.COM
.lab.netapp.com = ADNFSV4.LAB.NETAPP.COM
.sim.netapp.com = ADNFSV4.LAB.NETAPP.COM
.adnfsv4.lab.netapp.com = ADNFSV4.LAB.NETAPP.COM
[logging]
FILE=/var/krb5/kdc.log
It is important to realize that:
- The encryption type specifiers ( and default_tkt_enctypes = des-cbc-md5 ; or des-cbc-crc and default_tgs_enctypes = des-cbc-md5 ; or des-cbc-crc) cannot be omitted. Microsoft states:
Only DES-CBC-MD5 and DES-CBC-CRC encryption types are available for MIT interoperability.
- The [domain_realm] section that maps DNS domain names to the Active Directory realm is critical.
- Active Directory only supports upper case realms. This is the case even though the screen shots of the Windows 2000 Active Directory tree should a lower case domain name.
You want to make sure gssd is running on the Linux client:
$ ps -eaf | grep gssd
root 2587 1 0 15:37 ? 00:00:00 rpc.gssd -m
If it is not, then you will need to start gssd:
# cd /
# /etc/init.d/rpcgssd stop
# /etc/init.d/rpcgssd start
You may have to set the /etc/sysconfig/nfs file to enable Kerberized NFS. Do:
# echo "SECURE_NFS=yes" > /etc/sysconfig/nfs
That takes care of the KDC and NFS client. What of the filer?
ONTAP supports the capability of the filer to directly join an Active Directory realm without having to use the ktpass command to produce a keytab. Indeed, if you are running CIFS as well as NFS, you have joined the Active Directory realm directly as a consequence of running "cifs setup" at the filer's command line.
Prior to joining the Active Directory realm,
we need to set the dns server in the filer's resolv.conf file (in the etc subdirectory of the root volume [often /vol/vol0])
to refer to the IP address of the Active Directory server. If
you do not do this, the filer will be unable to resolve the Active Directory realm to the Active Directory server. This does not mean the file has to have its DNS domain name be the same as the Active Directory realm it belongs to. The example we've been working through assumes the DNS domain name and the Active Directory realm are different.
Invoke nfs setup on the filer's command line interface:
mre1> nfs setup
Enable Kerberos for NFS? y
The filer supports these types of Kerberos Key Distribution Centers (KDCs):
1 - UNIX KDC
2 - Microsoft Active Directory KDC
Enter the type of your KDC (1-2): 2
The default name of this filer will be 'MRE1'.
Do you want to modify this name? [no]:
The filer will use Windows Domain authentication.
Enter the Windows Domain for the filer []:ADNFSV4.LAB.NETAPP.COM
ADNFSV4.LAB.NETAPP.COM is a Windows 2000(tm) domain.
In order to create this filer's domain account, you must supply the name
and password of an administrator account with sufficient privilege to
add the filer to the ADNFSV4.LAB.NETAPP.COM domain.
Please enter the Windows 2000 user [Administrator@ADNFSV4.LAB.NETAPP.COM]:
Password for Administrator:
CIFS - Logged in as administrator@ADNFSV4.LAB.NETAPP.COM.
CIFS - Updating existing filer account
'cn=mre1,cn=computers,dc=adnfsv4,dc=lab,dc=netapp,dc=com'
CIFS - Connecting to domain controller.
Welcome to the ADNFSV4 (ADNFSV4.LAB.NETAPP.COM) Windows 2000(tm) domain.
Kerberos now enabled for NFS.
NFS setup complete.
If you have previously done a "cifs setup", then you won't be prompted for the realm, host name, and administrator login, because CIFS does that. Both "nfs setup" and "cifs setup" create the "nfs/mre1.sim.netapp.com" principal on the Active Directory KDC. If you go back to the Windows 2000 server, you will see an entry for
MRE1 in the
Computer folder under the
adnfsv4.lab.netapp.com tree.
(Note that if the Active Directory KDC is running Windows 2003, "nfs setup" will ask an additional question:
Active Directory container for filer account? [cn=computers]:
Simply push the enter key).
When using Active Directory as the KDC, no krb5.keytab is created. Instead, when the mahcine account
MRE1 is created in the Active Directory database, the password (randomly generated by Data ONTAP) for
MRE1 is recorded in stable storage on a file in on the filer. The password for
MRE1 is used to obtain service keys for CIFS and NFS, and potentially other Kerberized network services. Even if the password for
administrator changes, the filer will be able to obtain service keys for CIFS and NFS.
You also need to export the volumes with the sec=krb5 or sec=krb5i (Linux currently does not support sec=krb5p.). krb5 is plain authentication, krb5i is authentication with integrity protection on the requests and responses, and krb5p is like krb5i but also encrypts the requests and responses. If using NFSv4, it is critical to note if an ancestor and descendent directory are both exported, and the descendent is exported with sec=
flavorX then the ancestor must include flavorX in its list of flavors. So for example:
/vol/vol0 -sec=sys
/vol/vol0/home -sec=krb5
will break most NFSv4 clients. You will need to change this to:
/vol/vol0 -sec=sys:krb5
/vol/vol0/home -sec=krb5
At this point you should be ready to try some NFS mounts. I suggest trying the sanity test shell script listed earlier in this article and put the Linux NFS client through its paces. First you want to kinit to a user:
$ kinit jsmith
Password for jsmith@ADNFSV4.LAB.NETAPP.COM:
Then run the shell script:
$ sh sanity.sh mre1.sim /vol/vol0/home /mnt